
Tout un chacun est utilisateur de données contenues dans un SGBD (Système de Gestion de Bases de Données) qui renferme tout ou partie de données plus ou moins confidentielles. Ces données peuvent être par exemple un numéro de carte de crédit dans le cadre d’une plateforme de E-Commerce, un numéro d’assuré AVS dans un applicatif public ou une fiche de salaire dans un logiciel métier. L’ensemble de ces données est structuré et stocké dans des tables dites relationnelles au sein de votre base de données. Les données sont ainsi transmises au logiciel qui les exploite par une requête d’accès appelée SQL (Structured Query Language) via un accès utilisateur + mot de passe. La majeure partie du temps ces données sont stockées en clair sur les serveurs ou cryptées pour les plus sensibles d’entre elles via une clé de hash à l’intérieur des tables utilisateurs. Ces données sont ainsi accessibles pour l’ensemble des utilisateurs avec les mêmes identifiants. Dès lors l’ensemble des personnes connaissant les accès peuvent lire, modifier ou extraire des données pouvant être potentiellement sensibles. Ces données sont stockées la plupart du temps sur de multiples environnements (développement, testing, validation, production) et il existe de nombreux risques en stockant ces données dites sensibles sur toutes ces machines.

Solutions du marché
Les données sensibles stockées dans vos bases de données sont nécessaires à vos équipes pour développer vos logiciels, améliorer leurs fonctionnalités voir même pour vous aider dans le cadre de support utilisateur. Ces utilisateurs ayant des privilèges dits élevés ont donc accès à des données dites sensibles de la même manière qu’un administrateur d’un serveur de votre entreprise a accès à l’ensemble des données classées de par son rôle de gestion des utilisateurs. Dès lors, il faut avoir une confiance sans limite en ces personnes pour leur donner accès à des données sensibles. On sait que l’espionnage industriel vient très souvent de l’intérieur et qu’il peut coûter très cher ; rappelez-vous cet informaticen travaillant pour une banque Genevoise cachant des avoirs qui n’étaient pas déclarés au fisc des pays de leur propriétaire. L’intéressé avait fait une simple exportation des données auxquelles il avait accès, les avaient copiées sur un CD et les avaient vendues aux états intéressés. Hormis le caractère politique de cette affaire, il apparait que l’inculpé exploitait des données auxquelles il avait accès chaque jour dans le cadre de son travail.
- Dès lors quelles alternatives se portent à vous afin de garantir l’accès aux données aux personnes qui en ont besoin sans pour autant crypter chaque donnée stockée dans votre SGBD (donnée qui devra dans tous les cas être décryptée afin d’être interprétée par votre logiciel métier) ?
- Quelles sont les possibilités mises sur le marché donnant l’accès à des données plus ou moins complètes selon l’utilisateur connecté ?
- Quelles sont les différentes méthodes présentes sur le marché pour réaliser ces actions ?
Vous en apprendrez plus, nous l’espérons, grâce à notre article et notamment aux améliorations apportées par Microsoft dans sa dernière mouture de SQL Server 2016.
N’hésitez pas à commenter et nous donner vos retours sur les différentes technologies et logiciels présentés dans ce post.
Data Masking
Sous le nom de Data Masking se trouve en réalité, une technologie et un marché assez fermé d’outils permettant de rendre tout ou partie des données illisibles ou du moins offusquée. Par exemple l’adresse e-mail prenom.nom@domaine.ch deviendrait prenxxxxx@xxxx.ch. On appelle cela couramment l’anonymisation des données. Ces données peuvent ainsi être disponibles de manière panachée selon l’utilisateur qui accède à la donnée et ainsi garantir la sécurité d’accès aux seules personnes nécessitant un accès complet.
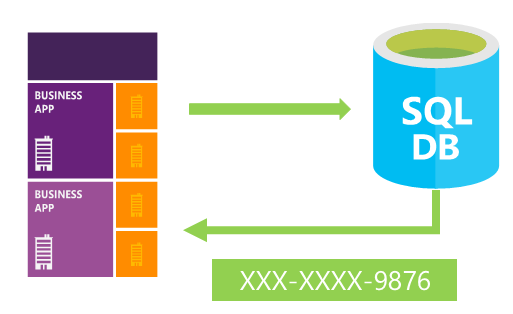 SQL Server 2016 Data Masking
SQL Server 2016 Data Masking
Etude Gartner et fournisseurs actifs
Selon le cabinet Gartner qui référencie sous le terme DMT (Data Making Technology) dans son dernier Magic Quadrant de décembre 2015 (ID : G00273093) les principaux fournisseurs mondiaux de solutions, le marché peut se diviser en deux grands groupes de solutions, celles dites de « Static Data Masking » et celles de « Dynamic Data Masking ». Lorsque la première catégorie d’outils utilise des algorithmes de réécriture de données sur une base de données copiée de l’originale (et non pas la production), la seconde traite le flux de données en temps réél via un applicatif traitant et adaptant le rendu. On peut citer de très bonnes solutions du marché international comme les produits des sociétés Informatica, Delphix ou Camouflage faisant partie des solutions les plus abouties du marché en mode multi-SGBD, mais aussi quelques solutions propres à l'un ou l’autre SGBD comme celles d’Oracle, Net 2000 ou Hexatier. Chacune de ces solutions répond très clairement à des besoins métiers dans des environnements spécifiques mais à chaque fois une surcouche est ajoutée dans le traitement des données, ce qui a pour effet de ralentir l’accès à ces dernières.
Wikipedia propose un article très complet à ce sujet en anglais sur son site web parlant notamment de solutions alternatives notamment celles qui s’appuient sur la puissance du cloud pour l’anoymisation des données « Data Masking in the Cloud ».
Nous allons nous attarder sur le modèle Dynamic Data Masking et notamment sur les nouvelles fonctionnalités offertes par SQL Serveur 2016 dans ce domaine d’activités. Alors qu’il était impossible dans les versions précédentes du SGBD Microsoft de réaliser une anoymisation des données « obfuscation » la version 2016 a mis le paquet et permet ainsi de manière entièrement native de créer des règles d’affichage de données selon l’utilisateur SQL connecté. Ainsi par exemple dans le cadre d’un dossier médical (e-Health), votre médecin pourra voir et saisir l’ensemble des données lié à votre visite dans son cabinet alors que sa secrétaire ne verra qu’une seule partie des données et de manière anonymisée. A l’heure de la protection des données et de la sphère privée, cette thématique devient de plus en plus pressante pour les développeurs de logiciels.
Data Compliance et futur…
Alors même que des directives de « compliance » sont édictées par les grands groupes, les PME étaient jusqu’à lors dans l’impossibilité de réaliser simplement des accès aux données granulaires. Cette période est dorénavant révolue, du moins pour les sociétés travaillant avec SQL Server !
Découvrons ensemble de manière sommaire la simplicité d’utilisation de ces nouvelles fonctionnalités.
SQL Serveur 2016 propose nativement 4 modes de traitements de données permettant ainsi d’afficher partiellement les données sensibles :
- Default cachant l’ensemble des données selon des paramètres donnés
- E-mail Méthode affichant la première lettre d’une adresse e-mail et le suffix .com sous un format « [email protected] »
- Random Méthode générant un chiffre contenu entre 2 valeurs de manière aléatoire
- Custom string La méthode la plus ouverte permettant de définir ses propres expressions régulières de traitement des données selon une structure toutefois préformatée
Permission d’accès aux données
Alors que pour l’ensemble des produits du marché, une surcouche interagie entre le SGBD et l’applicatif métier afin de réaliser le rendu du flux, dans SQL Server 2016 ces données sont traitées en direct par le moteur SQL. Ainsi selon les autorisations d’accès de l’utilisateur, ce dernier se verra afficher les données en clair ou offusquées. Afin de définir quelle donnée doit être cachée la nouvelle fonction SQL « ADD MASKED » a fait son apparition. Les administrateurs continueront de voir les données alors que les utilisateurs sans privilège ne verront que les données partiellement affichées.
Cette fonctionnalité tout comme d’autres fonctionnalités « advanced » présentes par le passé uniquement dans les versions Standards et Entreprise de la gamme Microsoft ont été activées également pour la version Express (gratuite) depuis la version SP1 de SQL Server 2016. Dès lors plus aucune raison de ne pas passer à 2016 et tester ce nouveau lot d’améliorations.
Exemple pratique
Nous avons installé une machine virtuelle tournant sur Microsoft Windows 2016 Standard et le SGBD SQL Server 2016 version Express. Puis nous avons encore installé le SP1 afin de garantir l’accès aux fonctionnalités verrouillées avant le Service Pack. Nous avons ensuite téléchargé la base de données d’exemple de chez Microsoft appelée AdventureWorks Databases – 2014. Dans notre exemple nous allons d’abord modifier les données affichées pour les colonnes prénom et nom de la table personnes puis modifier l’adresse e-mail de la table portant le même nom. Une fois cette opération effectuée, nous allons créer un utilisateur en lecture seule sur la base et allons afficher les données en mode administrateur puis en mode utilisateur "read-only".
-- Create some data masking for my confidential columns with the masking functions USE [AdventureWorks2014] GO ALTER Table [Person].[Person] ALTER COLUMN FirstName ADD MASKED WITH (FUNCTION = 'default()') ALTER Table [Person].[Person] ALTER COLUMN LastName ADD MASKED WITH (FUNCTION = 'partial(5, "XXXXXX", 0)') ALTER Table [Person].[EmailAddress] ALTER COLUMN EmailAddress ADD MASKED WITH (FUNCTION='email()') -- Create a user named DM_ReadOnly and add this user to the AdventureWorks2014 Database as a read only user USE [AdventureWorks2014] go CREATE USER DM_ReadOnly WITHOUT LOGIN USE [AdventureWorks2014] GO ALTER ROLE [db_datareader] ADD MEMBER [DM_ReadOnly] GO -- Execute a select statement as Administrator or sys_admin (Data Clean) SELECT TOP (3) FROM [AdventureWorks2014].[Person].[Person] SELECT TOP (3) FROM [AdventureWorks2014].[Person].[EmailAddress] -- Execute a select statement as DM_ReadOnly (Data Mask) EXECUTE AS USER='DM_ReadOnly' SELECT TOP (3) FROM [AdventureWorks2014].[Person].[Person] SELECT TOP (3) FROM [AdventureWorks2014].[Person].[EmailAddress]
Le résultat en vidéo
Limitation sécuritaire et brute-force
La technologie de Dynamic Data Masking est designée pour simplifier le développement d’applications en limitant l’affichage de données sensibles via une application. Même si cette technologie permet de limiter l’accès à certaines données, il est a noter qu’un utilisateur non-privilégié pourrait via des requêtes ad hoc gagner un accès à ces données via une technique de brute force.
Vous retrouvez un très bon article à ce sujet sur le site web de Microsoft : https://docs.microsoft.com/en-us/sql/relational-databases/security/dynamic-data-masking
Afin de garantir le cryptage des données « extrêmement sensibles » nous vous recommandons d’utiliser en plus l’une des autres nouvelles fonctionnalités natives de SQL Server 2016 appelée « Always Encrypted » pour laquelle nous reviendrons dessus lors d’un prochain blog post.
Conclusion
Microsoft a fait tout juste avec cette version 2016 et est à l’écoute d’un marché en perpétuel changement. La société américaine essaye en plus de gommer la différence de fonctionnalités entre ses versions en retravaillant son business model selon les puissances et volumes de données à traiter à l’instar de leur proposition sur leur Cloud Azure et ainsi s’ouvrir un nouveau à vivier de clients plutôt enclin à des solutions Open Source jusqu’à lors.
Bon code et à votre disposition pour tout complément d’informations.